| ‚Qپ@‘½ژںŒ³ٹm—¦•ھ•zپ@پ@ | |
| f-denshi.com چإڈIچXگV“ْپF11/06/02 | |
| ƒTƒCƒgŒںچُ | |
پm1پnپ@•،گ”Œآ‚جٹm—¦•دگ”‚©‚瑽ژںŒ³‚جٹm—¦•دگ”‚ًچى‚èڈo‚·‚±‚ئ‚ًچl‚¦‚و‚¤پB—ل‚¦‚خپC‚ا‚ج–ت‚à“™ٹm—¦‚إŒ»‚ê‚éگ³ژl–ت‘ج‚جƒTƒCƒRƒچ‚ئ—§•û‘ج‚جƒTƒCƒRƒچ‚ج2‚آ‚ً“¯ژ‚ةگU‚ء‚ؤپCگ³ژl–ت‘ج‚جڈo–ع‚ھxپC‚©‚آپC—§•û‘ج‚جڈo–ع‚ھy‚ئ‚ب‚邱‚ئ‚ًپCƒxƒNƒgƒ‹گ¬•ھ‚ئ‚µ‚ؤپC
| پ@X پپ | X | پ@[‚QژںŒ³ٹm—¦•دگ”]پCپ@x پپ | x | پ@[‚QژںŒ³ژ–ڈغ] | ||||
| Y | y |
‚ئڈ‘‚‚±‚ئ‚ئ‚µپC‚±‚ê‚ً‚QژںŒ³ٹm—¦•دگ”‚ئ’è‹`‚·‚éپB‚½‚ؤƒxƒNƒgƒ‹‚إ’è‹`‚·‚é‚ھپCƒXƒyپ[ƒX‚ج“sچ‡ڈمپC‚و‚±ƒxƒNƒgƒ‹‚إپC
tx پپپ@(x,y)
‚ئ‚àڈ‘‚پB‚µ‚©‚µپCچ،Œم—p‚¢‚邱‚ئ‚ة‚ب‚éچs—ٌ‚جچ¬‚¶‚ء‚½ŒvژZژ®‚ج’†‚إ‚حپCx ‚ح‚½‚ؤƒxƒNƒgƒ‹‚إ‚ ‚邱‚ئ‚ًژv‚¢ڈo‚·•K—v‚ھ‚ ‚éپB
ٹm—¦ٹضگ”‚حپC
P(X=x,Y=y)پپP(X =x)
‚ج‚و‚¤‚ةڈ‘‚¢‚ؤٹg’£‚³‚ê‚éپB‚±‚ê‚ً“¯ژٹm—¦ٹضگ”‚ئŒؤ‚شپB(—£ژUٹm—¦•دگ”‚ج‚ئ‚«‚ح“¯ژ(ٹm—¦)–§“xٹضگ”f(x)پپf(x,y) ‚إ‚à‚ ‚éپB)پ@‚Qژي‚جƒTƒCƒRƒچ‚جڈo–ع‚إ’è‹`‚³‚ê‚é‚QژںŒ³ٹm—¦•دگ”X ‚جژو‚蓾‚é’l(چھŒ¹ژ–ڈغ)‚حژں‚ج‚ئ‚¨‚è‚ئ‚ب‚éپB(ƒXƒyپ[ƒX‚ج“sچ‡ڈم‚و‚±ƒxƒNƒgƒ‹‚إڈ‘‚)
(1,1)پ@پCپ@(2,1)پ@پCپ@(3,1)پ@پCپ@(4,1)
(1,2)پ@پCپ@(2,2)پ@پCپ@(3,2)پ@پCپ@(4,2)
(1,3)پ@پCپ@(2,3)پ@پCپ@(3,3)پ@پCپ@(4,3)
(1,4)پ@پCپ@(2,4)پ@پCپ@(3,4)پ@پCپ@(4,4)
(1,5)پ@پCپ@(2,5)پ@پCپ@(3,5)پ@پCپ@(4,5)
(1,6)پ@پCپ@(2,6)پ@پCپ@(3,6)پ@پCپ@(4,6)
ƒTƒCƒRƒچ‚ھ‹دژ؟‚إ‚ ‚ê‚خپC‚±‚ê‚ç24’ت‚è‚جڈo–ع‚ھ“™ٹm—¦‚إ‹N‚±‚èپC‚±‚ê‚ç‚·‚ׂؤپCP(Xپپx)پپ1/24‚إ‚ ‚é‚ئ‚µ‚ؤ‚و‚¢‚¾‚낤پB‚±‚ج“¯ژٹm—¦(–§“x)ٹضگ”‚ًگ}ژ¦‚·‚é‚ئژں‚ج‚و‚¤‚ةڈ‘‚‚±‚ئ‚ھ‚إ‚«‚éپB(گش‚¢“_ˆبٹO‚ج‚ئ‚±‚ë‚إ‚حP(X =x)پپ0)
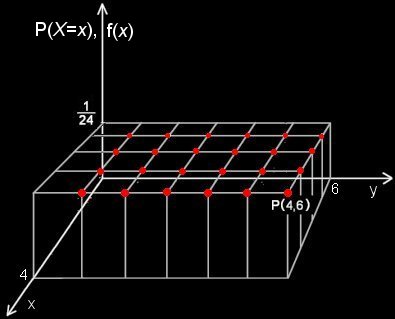
پm‚Qپnپ@‚±‚±‚إپC‚ا‚؟‚ç‚©ˆê•û‚جٹm—¦•دگ”‚ج’l‚ًŒإ’肵‚½پC
| پ@P(X=x)پپ | P(X=x,Y=y)پ@پپf1(x)پ@پ@پ©پ@X‚حx‚إ‚ ‚é‚ھپCY‚ح‰½‚إ‚à‚و‚¢ |
| پ@P(Y=y)پپ | P(X=x,Y=y)پ@پپf2(y)پ@پ@پ©پ@Y‚حy‚إ‚ ‚é‚ھپCX‚ح‰½‚إ‚à‚و‚¢ |
‚ًXپC‚ـ‚½‚حY‚جژü•سٹm—¦(–§“x)ٹضگ”‚ئŒؤ‚شپBP(Y=y)‚ً’è‹`‚ةڈ]‚ء‚ؤŒvژZ‚·‚é‚ئپC
پ@پ@P(Y=y)پپP(1,y)پ{P(2,y)پ{P(3,y)پ{P(4,y)پپ4/24پ@
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پiyپپ1,2,3,4,5,6‚ج‚ئ‚«پj
پ@پ@P(Y=y)پپ0پ@پ@پ@پ@پ@پiyپپ1,2,3,4,5,6ˆبٹO‚ج‚ئ‚«پjپ@
پ@پ@پ@پ@پ@پ@پ@پ@پ@پھ‚±‚ê‚حژ©–¾‚ب‚ج‚إچl‚¦‚ب‚‚ؤ‚à‚و‚¢
‚إ‚ ‚èپCP(Y=y)پپ1/6پ@پiyپپ1,2,3,4,5,6)پ@‚ئ‚ب‚ء‚ؤ‚¢‚é‚ھپC‚±‚ê‚حپCگ³‚S–ت‘جƒTƒCƒRƒچ‚جڈo–ع‚ً–³ژ‹‚µپCگ³‚U–ت‘ج‚جƒTƒCƒRƒچ‚جڈo–ع‚¾‚¯‚ً‚¾‚¯‚ًچl‚¦‚邱‚ئ‚ة“™‚µ‚¢پB
ˆê•ûپC‚QژںŒ³‚ج—فگد•ھ•zٹضگ”‚حپC
F(x,y)پپP(Xپ…x)پپP(Xپ…x,Yپ…y)
‚ئ’è‹`‚³‚êپC“¯ژ•ھ•zٹضگ”‚ئ‚àŒؤ‚خ‚ê‚éپB“¯ژ–§“xٹضگ”‚ئ‚حپC
F(x,y)پپ f(xi,yj)پ@پ@پ@[—£ژU]
‚ئ‚¢‚¤ٹضŒW‚ھ‚ ‚éپB‚³‚ç‚ةپC
F1(x)پپF(x,پ‡)پپP(Xپ…x)
F2(y)پپF(پ‡,y)پپP(Yپ…y)
‚ً‚»‚ꂼ‚êپCXپC‚ـ‚½‚حY‚جژü•س•ھ•zٹضگ”‚ئ‚¢‚¤پB
–â‘èپFپ@“¯ژ•ھ•zٹضگ”‚ًگ}ژ¦(ƒCƒپپ[ƒW)‚¹‚وپB
پm‚Rپnپ@‘½ژںŒ³ٹm—¦•دگ”‚ھکA‘±‚إ‚ ‚éڈêچ‡‚à—£ژU“I‚بڈêچ‡‚ئ“¯—l‚ةژں‚ج’è‹`‚ً“±“ü‚·‚邱‚ئ‚ھ‚إ‚«‚éپB
‚QژںŒ³‚ج“¯ژ•ھ•zٹضگ”F(x,y)‚حپC
F(x,y)پپP(Xپ…x)پپP(Xپ…x,Yپ…y)
‚ئ‚·‚ê‚خ‚و‚¢پB“¯ژٹm—¦–§“xٹضگ”f(x,y)‚ئ‚جٹضŒW‚حپC
F(x,y)پپ f(x,y)dydxپ@پ@پ@پ@[کA‘±ٹm—¦•دگ”]
پiپ@f(x,y)پپ0پCxپCyپƒ0پ@‚إ‚ ‚ê‚خپCگد•ھ”حˆح‚حپCxپCyپ„0‚إچs‚¦‚خ‚و‚¢پBپj
‚¨‚و‚رپC
f(x,y) پپ پف2 F(x,y) پفxپفy
‚إ‚ ‚éپBژü•س–§“xٹضگ”fi(x)‚حپC
f1(x)پپ f(x,y)dy
f2(y)پپ f(x,y)dx
‚ئ‚ب‚éپB
پm‚Sپnپ@ژہ‚حپC‚±‚±‚ـ‚إچl‚¦‚ؤ‚«‚½‚Q‚آ‚جƒTƒCƒRƒچ‚جڈo–ع‚ة‚آ‚¢‚ؤ‚حپCˆأ–ظ‚ج—¹‰ً‚ئ‚µ‚ؤپC‚¨Œف‚¢‚ة‚»‚جڈo–ع‚ة‰e‹؟‚ً‹y‚ع‚µچ‡‚ي‚ب‚¢‚ئ‚µ‚ؤٹm—¦‚ًŒvژZ‚ً‚µ‚ؤ‚«‚½پB‚±‚ج‚و‚¤‚ة‚Q‚آ(ˆبڈم)‚جٹm—¦•دگ”‚جٹش‚جٹضŒW‚ھ‚ب‚¢‚±‚ئ‚ً‚Q‚آ‚جٹm—¦•دگ”X,Y‚ھ“ئ—§‚إ‚ ‚é‚¢‚¢پCگ”ٹw“I‚ة‚حژں‚ج‚و‚¤‚ة’è‹`‚·‚éپB
|
ٹm—¦•دگ”XپCY‚ھ”Cˆس‚جژ–ڈغ‚ة‘خ‚µ‚ؤپC P(X=x,Y=y)پپP(X=x)P(Y=y)پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@[—£ژU]‚ ‚é‚¢‚حٹm—¦–§“x‚ة‚آ‚¢‚ؤپC پ@پ@پ@پ@f(x,y)پپf1(x)f2(y)پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پm—£ژU‚ـ‚½‚حکA‘±پn ‚ھگ¬‚è—§‚آ‚ئ‚«پCX‚ئY‚ح“ئ—§‚إ‚ ‚é‚ئ‚¢‚¤پB |
گو’ِ‚ج‚Qژي—ق‚جƒTƒCƒRƒچ‚ج—ل(—£ژU•دگ”)‚إپCڈo–ع‚ج‘g‚ھ(1,3)‚ئ‚ب‚éٹm—¦‚ھP(X=1,Y=3)پپ1/24‚ئ‚ب‚éچھ‹’‚حپCگ³ژl–ت‘جƒTƒCƒRƒچ‚ھ‚PپC‚©‚آ—§•û‘جƒTƒCƒRƒچ‚ھ3‚ئ‚ب‚éٹm—¦‚ًپC
P(X=1)P(Y=3)پپ(1/4)¥(1/6)پپپ@1/24پ@پپP(X=1,Y=3)
‚ج‚و‚¤‚ةŒvژZ‚ة‚µ‚ؤ‚¨‚èپC‚±‚ج‚و‚¤‚بŒvژZ•û–@‚ًگ³“–‰»‚·‚邽‚ك‚ة“ئ—§‚ئ‚¢‚¤ٹT”O‚ھ—pˆس‚³‚ê‚ؤ‚¢‚éپB
پm‚Tپnپ@“ئ—§‚إ‚ب‚¢‚ئ‚«‚حپCڈًŒڈ•tٹm—¦ٹضگ”پC
P(X=x|Y=y)پك P(X=x,Y=y) P(Y=y)
‚ً—p‚¢‚ب‚¯‚ê‚خ‚ب‚ç‚ب‚¢پB‚±‚±‚إپC‹Lچ†پFP(X=x|Y=y)پ@‚ئ‚حپCY=y ‚ھژہŒ»‚µ‚ؤ‚¢‚éڈًŒڈ‚ج‰؛‚إپCX=x ‚ئ‚ب‚éٹm—¦‚ًˆس–،‚·‚éپBڈمژ®‚ً•دŒ`‚µ‚ؤپC
P(X=x,Y=y)پپP(Y=y)P(X=x|Y=y)
‚ئ‚·‚ê‚خپCٹm—¦•دگ”X,Y‚ھ“ئ—§‚ئ‚¢‚¤‚±‚ئ‚حپC
P(X=x|Y=y)پپP(X=x)پ@پ@پ@پ@پ@[X,Y“ئ—§]
‚ئŒ¾‚¢’¼‚·‚±‚ئ‚à‚إ‚«‚éپB
کA‘±ٹm—¦•دگ”‚ج‚ئ‚«‚حڈًŒڈ•tٹm—¦–§“xٹضگ”‚حپC
f1(x|y)پك f(x,y) پ@پ@پ@پ@پ@پجپ@پ@پ@f(x,y)پپf1(x|y)f2(y) f2(y)
‚ئ’è‹`‚·‚éپB—£ژU“Iٹm—¦•دگ”‚جڈêچ‡‚ئ“¯—l‚ةپCٹm—¦•دگ”X,Y‚ھ“ئ—§‚ئ‚¢‚¤‚±‚ئ‚حپC
f1(x|y)پپf1(x)
‚ئڈ‘‚¯‚邱‚ئ‚ئ‚µ‚ؤ‚à‚و‚¢پB
ˆبڈم‚ـ‚ئ‚ك‚é‚ئپC
| *–¼ڈج¥‹Lچ† | —£ژU | کA‘± | ||||||||||||||||
| “¯ژ•ھ•zٹضگ” F(x,y) |
|
|
||||||||||||||||
| ژü•س•ھ•zٹضگ” Fi |
|
|
||||||||||||||||
| “¯ژٹm—¦(–§“x)ٹضگ” f(x,y) |
P(X=x,Y=y)پپf(x,y) ‚ـ‚½‚حپCP(X=xi,Y=yj)پپf(xi,yj) |
|
||||||||||||||||
| ژü•سٹm—¦(–§“x)ٹضگ” fi |
|
|
||||||||||||||||
| ڈًŒڈ•tٹm—¦(–§“x)ٹضگ” fi(x|y) |
|
|
*پ@“¯ژٹm—¦ٹضگ”‚ً“¯ژ•ھ•zپC‘¼‚ة‚àژü•سٹm—¦–§“xٹضگ”‚ًژü•س–§“xٹضگ”‚ئŒؤ‚شگl‚à‚¢‚é‚ب‚اپC‚â‚âپC‚±‚ج•س‚ج—pŒê‚ح“ˆê‚³‚ê‚ؤ‚¢‚ب‚¢پB
پm‚Uپnپ@ˆبڈم‚جکb‚جnژںŒ³ٹm—¦•دگ”‚ض‚جٹg’£‚ح“‚‚ب‚¢‚ج‚إڈعڈq‚ح‚µ‚ب‚¢پB
پm‚Pپnپ@ژں‚ة“ئ—§‚بٹm—¦•دگ”‚جXپCY‚©‚çپC‚»‚جکaپC
ZپپX+‚x
‚ًگV‚½‚بٹm—¦•دگ”Z‚ئ‚µ‚ؤ’è‹`‚·‚邱‚ئ‚ًچl‚¦‚éپBگو’ِ‚ـ‚إ‚حپCٹeƒTƒCƒRƒچ‚جڈo–ع‚ًƒxƒNƒgƒ‹‚جٹeگ¬•ھ‚ئ‚ف‚ب‚µ‚½‚ھپCچ،“x‚ح‚»‚جکa‚ًˆê‚آ‚جگ”‚ة‘خ‰‚³‚¹‚邱‚ئ‚ًچl‚¦‚éپB‚·‚é‚ئپCگو‚ج24‚ئ‚¨‚è‚جxپپ(x,y) ‚ة‘خ‚µ‚ؤپCxپ{yپ@‚حپC
| (x,y) | پث | x+y |
| (1,6)پ@پCپ@(2,6)پ@پCپ@(3,6)پ@پCپ@(4,6) (1,5)پ@پCپ@(2,5)پ@پCپ@(3,5)پ@پCپ@(4,5) (1,4)پ@پCپ@(2,4)پ@پCپ@(3,4)پ@پCپ@(4,4) (1,3)پ@پCپ@(2,3)پ@پCپ@(3,3)پ@پCپ@(4,3) (1,2)پ@پCپ@(2,2)پ@پCپ@(3,2)پ@پCپ@(4,2) (1,1)پ@پCپ@(2,1)پ@پCپ@(3,1)پ@پCپ@(4,1) |
7پ@پ@پCپ@پ@8پ@پ@پCپ@پ@9پ@پ@پCپ@ 10 6پ@پ@پCپ@پ@7پ@پ@پCپ@پ@8پ@پ@پCپ@پ@9 5پ@پ@پCپ@پ@6پ@پ@پCپ@پ@7پ@پ@پCپ@پ@8 4پ@پ@پCپ@پ@5پ@پ@پCپ@پ@6پ@پ@پCپ@پ@7 3پ@پ@پCپ@پ@4پ@پ@پCپ@پ@5پ@پ@پCپ@پ@6 2پ@پ@پCپ@پ@3پ@پ@پCپ@پ@4پ@پ@پCپ@پ@5 |
‚ئ‚ب‚èپC‚±‚ê‚ç‚ھ“™ٹm—¦‚إ‹N‚«‚邱‚ئ‚ئ‚ب‚éپB‚·‚é‚ئپCZپپ{zپb2,3,4,5,6,7,8,9,10} ‚جٹm—¦(–§“x)ٹضگ”پCP(Z=z)پپP(X+Y=z) ‚ھپC
P(Z=2)پپ1/24پCپ@P(Z=3)پپ2/24پCپ@P(Z=4)پپ3/24پCپ@P(Z=5)پپ4/24پCپ@P(Z=6)پپ4/24
P(Z=7)پپ4/24پCپ@P(Z=8)پپ3/24پCپ@P(Z=9)پپ2/24پCپ@P(Z=10)پپ1/24پ@
‚إ—^‚¦‚ç‚ê‚邱‚ئ‚ة‚·‚é‚ئپCڈم‚جˆê——‚ئ’زهë‚ھچ‡‚¤پB(پ©گ³ژl–ت‘جپC—§•û‘ج‚جƒTƒCƒRƒچ‚ھ‹¤‚ة‘خڈج‚إ‹دˆê‚ب‚ç‚خپC‚±‚ج‚و‚¤‚ة‚ب‚é‚ئگM‚¶‚ؤ‚à•¶‹ه‚ح‚ ‚é‚ـ‚¢پB)پ@ٹm—¦•دگ”X,Y‚ة‚آ‚¢‚ؤ‚حپCٹm—¦ٹضگ”P(X=x)پCP(Y=y)‚ح‚»‚ꂼ‚êˆê’è’lپC1/4پC‚¨‚و‚رپC1/6‚ً‚ئ‚é’èگ”ٹضگ”(‚â‚â•sگ³ٹm‚بŒ¾‚¢•û‚¾‚ھ)‚إ‚ ‚é‚ھپC‚»‚جکaZ‚ة‚آ‚¢‚ؤپCP(Z=z)‚ح‚à‚ح‚âˆê’è‚ج’l‚ً•ش‚µ‚ؤ‚±‚ب‚¢پBٹm—¦•دگ”‚ھ’P‚ب‚é•دگ”‚إ‚ح‚ب‚¢ڈٹˆب‚إ‚ ‚éپB
ˆبڈم‚ج‚±‚ئ‚ًپCگ³‚S–ت‘جƒTƒCƒRƒچ‚ة‚آ‚¢‚ؤپCP(X=x)پپ1/4پCگ³‚U–ت‘جƒTƒCƒRƒچ‚ة‚آ‚¢‚ؤپCP(Y=y)پپ1/6‚إ‚ ‚邱‚ئ‚ة’چˆس‚µ‚ؤپCگ}‚ة•\‚ي‚·‚ئژں‚ج‚ئ‚¨‚è‚ئ‚ب‚éپBپ«—خ‚ج“_‚ھٹm—¦ٹضگ”‚ھ‚ئ‚é’lپB
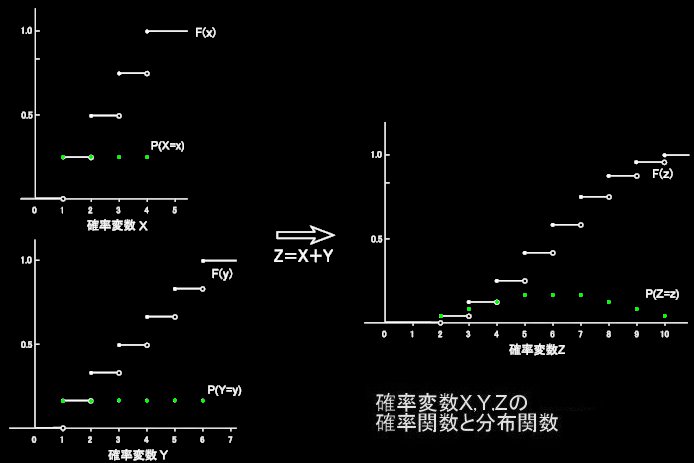
پm‚Qپnپ@ژں‚ةپC‚±‚ê‚ç‚ًˆê”ت‰»‚µ‚½‚¢‚ج‚¾‚ھپC‚ـ‚¸پCƒTƒCƒRƒچ‚ج–ع‚جکa‚ھ4‚ئ‚ب‚éٹm—¦‚ة‚آ‚¢‚ؤپC
P(Z=4)پپ P(X=x,Y=y)ƒآ(x+y=4)
پ@پ@پ@پ@پپ P(X=x) P(Y=y)ƒآ(x+y=4)
پ@پ@پ@پ@پپ P(X=4-y) P(Y=y) پ@پ@پ@پ@پ@پ@پ@(پ@پپ P(X=x)P(Y=4-x)پ@پ@پj
پپP(X=3)P(Y=1)پ{P(X=2)P(Y=2)پ{P(X=1)P(Y=3)پ{پ@پ@پ@P(X=0)P(Y=4)پ{P(X=-1)P(Y=5)پ{P(X=-2)P(Y=6)
پ@پ@پ@پ@
پپ 1 ¥ 1 پ{ 1 ¥ 1 پ{ 1 ¥ 1
پ{0¥ 1 پ{0¥ 1
پ{0¥ 1 6 6 6 4 6 4 6 4 6
پپ 3 24
(‚½‚¾‚µپCƒNƒچƒlƒbƒJپ[‚جƒfƒ‹ƒ^پFƒآ(z=x+y) ‚حپCzپپxپ{y ‚ً–‚½‚·‚ئ‚«‚ة‚PپC‚»‚¤‚إ‚ب‚¢‚ئ‚«‚ة‚ح‚O‚ً‚ئ‚éپB‚ـ‚½پCƒ°‚ح“Y‚¦•¶ژڑx,y‚ج‚ ‚ç‚ن‚éژ–ڈغ‚ة‚آ‚¢‚ؤکa‚ً‚ئ‚éپB)
‚ج‚و‚¤‚ةڈ‘‚¯‚邱‚ئ‚ًٹm”F‚µ‚ؤ‚¨‚پB
پm‚Rپnپ@‚·‚é‚ئپC‚±‚ê‚ً Zپپz ‚ئˆê”ت‰»‚µ‚½ڈêچ‡‚إ‚حپCٹm—¦ٹضگ”‚ج‘م‚ي‚è‚ةٹm—¦–§“xٹضگ”‚ج‹Lچ†‚إپCP(X=x)پ¨f1(x)پCP(Y=y)پ¨f2(y)‚ً—p‚¢‚ؤڈ‘‚‚ئپC
پ@f(z)پپ f1(x)f2(y)ƒآ(z=x+y)
پ@پ@پ@پپ f1(z-y)f2(y)پپ f1(x)f2(z-x)پ@پ@X,Y‚ھ“ئ—§‚ب‚ئ‚«
‚ئڈ‘‚¢‚ؤ‚و‚¢پB(‚±‚ج•س‚ح—Œnٹw•”‚R”Nگ¶‚‚ç‚¢‚ج“اژز‚ً‘z’肵‚½گà–¾‚ئ‚ب‚ء‚ؤ‚¢‚éپB)
‚±‚ê‚حکA‘±•دگ”‚جڈêچ‡‚ة‚àٹg’£‚³‚êپCX‚جٹm—¦–§“xٹضگ”‚ًf1(x)پCY‚جٹm—¦–§“xٹضگ”‚ًf2(y)‚ئ‚·‚é‚ئ‚«پC
f(z)پپ f1(x)f2(y)ƒآ(z-(x+y))dxdy
پ@پ@پ@پپ f1(z-y)f2(y)dyپ@پپ f1(x)f2(zپ|x)dxپ@پ@پ@X,Y‚ھ“ئ—§‚ب‚ئ‚«
‚ئ‚إ‚«‚éپB‚±‚±‚إپCƒfƒBƒ‰ƒbƒN‚جƒآٹضگ”‚جگ«ژ؟[#]پC
g(x)ƒآ(x-a)dx پپ g(a)
‚ً—p‚¢‚½پB(x‚إگد•ھ‚·‚é‚ئ‚«‚حپCƒآ(x-(z-y))پC‚ئ‚µ‚ؤپCy‚إگد•ھ‚·‚é‚ئ‚«‚حپCƒآ(‚™-(z-x))‚ئ‚µ‚ؤپCƒآٹضگ”‚جگ«ژ؟“K—p‚¹‚وپB)
پm‚Sپnپ@‚³‚ç‚ةٹm—¦•دگ”‚جگ”n‚ًˆê”ت‰»‚µ‚½ٹm—¦•ھ•z‚جکaپ@ZپپX1پ{¥¥¥پ{Xnپ@‚جڈêچ‡پCz=x1پ{¥¥¥پ{xnپ@‚ئ‚µ‚ؤپCZ‚جٹm—¦–§“xٹضگ”‚حپC
f(z)پپ ¥¥¥ f(x1پCx2پC¥¥¥پCxn)ƒآ(z-(x1+x2+¥¥¥+xn))dx1dx2¥¥¥dxn
پ@پ@پ@پپ ¥¥¥ f(z-(x2+¥¥¥+xn)پCx2پC¥¥¥پCxn)dx2¥¥¥dxn پ@پ@پ@پ@¥¥¥¥[*]
‚ئ‚ب‚éپB‚±‚ج•\ژ®‚إ‚حٹm—¦•دگ”X1پC¥¥¥پCXn‚ھ“ئ—§‚إ‚ب‚‚ئ‚à‚و‚¢‚ھپCٹm—¦•دگ”Xi‚ھŒف‚¢‚ة“ئ—§‚إ‚ ‚é‚ب‚ç‚خ‚³‚ç‚ةپC
f(z)پپ ¥¥¥ f1(z-(x2+¥¥¥+xn))f2(x2)¥¥¥fn(xn)dx2¥¥¥dxn
‚ج‚و‚¤‚بnŒآ‚ج‚P•دگ”ٹضگ”‚جگد‚جگد•ھ‚ة•ھ‰ً‚³‚ê‚邱‚ئ‚حٹm—¦•دگ”‚جگ”‚ھ‚QŒآ‚جڈêچ‡‚ئ“¯‚¶‚إ‚ ‚éپB‚±‚ê‚ً•ھ•zٹضگ”f1(x1),¥¥¥,fn(xn)‚ج‚½‚½‚فچ‚ف‚ئŒؤ‚شپB“ء‚ةپCnپپ2‚إ‚ ‚é‚ب‚ç‚خپC
f(z)پپ f1(zپ|x2)f2(x2)dx2پ@پ@پ@پ@پ@n=2‚ج‚½‚½‚فچ‚ف
‚ئ‚ب‚èپCگو’ِ‚ج“ئ—§‚ب‚Q‚آ‚جٹm—¦•دگ”‚جکa‚ج‚½‚½‚فچ‚ف‚ًچؤٹm”F‚إ‚«‚éپB‚ب‚¨پC’f‚ء‚ؤ‚ب‚¢‚ھپCپ}پ‡‚إ–§“xٹضگ”‚ح0‚ة‹ك‚أ‚‚à‚ج‚ئ‚µ‚ؤ‚¢‚éپB‚ـ‚½پCژû‘©ڈًŒڈ‚ب‚اچׂ©‚¢‚±‚ئ‚حپC‚ئ‚è‚ ‚¦‚¸‚±‚±‚إ‚ح‹C‚ة‚µ‚ب‚¢‚إ‚¨‚پB
پm‚Tپnپ@ˆê•ûپC(‘½ژںŒ³(—فگد))•ھ•zٹضگ”F(z)‚ة‚آ‚¢‚ؤ‚حپC
F(z)پپ ¥¥¥ z-(x2پ{¥¥¥پ{xn) f(x1پC¥¥¥پCxn)dx1¥¥¥dxn -پ‡
پ@پ@پپ ¥¥¥ dx2¥¥¥dxn z-(x2پ{¥¥¥پ{xn) f(x1پC¥¥¥پCxn)dx1 -پ‡
‚ئ‚·‚ê‚خ‚و‚¢‚±‚ئ‚حپC‚±‚ê‚ًz‚إ”÷•ھ‚·‚ê‚خپC[*]‚ئ‚ب‚邱‚ئ‚©‚ç‚ي‚©‚éپB‚ـ‚½پC•ھ•zٹضگ”‚ًژں‚ج‚و‚¤‚ة•\‹L‚·‚邱‚ئ‚à‚ ‚é‚ھپC“¯‚¶ˆس–،‚إ‚ ‚éپB
| پ@P(Zپ…z)پپP(X1پ{¥¥¥پ{Xnپ…z)پپ | f(x1پC¥¥¥پCxn)dx1¥¥¥dxn | |
| x1پ{¥¥¥پ{xnپ…z |
‚±‚ê‚ç‚جژ®‚ة‚¨‚¢‚ؤ‚àپCٹm—¦•دگ”‚ھ“ئ—§‚إ‚ ‚ê‚خپCf(x1پCx2پC¥¥¥پCxn) پ@پثپ@f1(x1)f2(x2)¥¥¥fn(xn) ‚ئ‚إ‚«‚邱‚ئ‚حŒ¾‚¤‚ـ‚إ‚à‚ب‚¢پB
‚±‚ê‚حŒ‹‰ت‚¾‚¯‚ـ‚ئ‚ك‚ؤ‚¨‚پB
| Zپپ | f(z) | f(z)پ@X,Y‚ھ“ئ—§ | ||||||||
| Xپ{Y |
|
|
||||||||
| Xپ|Y |
|
|
||||||||
| XY |
|
|
||||||||
| X/Y |
|
|
||||||||
گà–¾‚حڈب—ھ‚·‚éپB‚ ‚µ‚©‚炸پB